[언론보도] 정교민 교수, 서울대·KAIST, '낚시성 기사' 잡아내는 딥러닝 모델 기술 개발(전자신문,2019.01.21)
내용과 동떨어진 과장된 제목으로 네티즌의 클릭을 유도하는 '낚시성 기사'를 걸러낼 수 있는 기술이 개발됐다. 포털이나 검색 사이트 보조 시스템으로 활용할 수 있는 기술이다.
KAIST는 차미영 전산학부 교수가 정교민 서울대 전기정보공학부 교수와 공동으로 딥러닝 기술을 활용해 제목과 내용이 다른 기사를 가려내는 기술을 개발, 낚시성 기사 선별 모델을 구현했다고 21일 밝혔다.
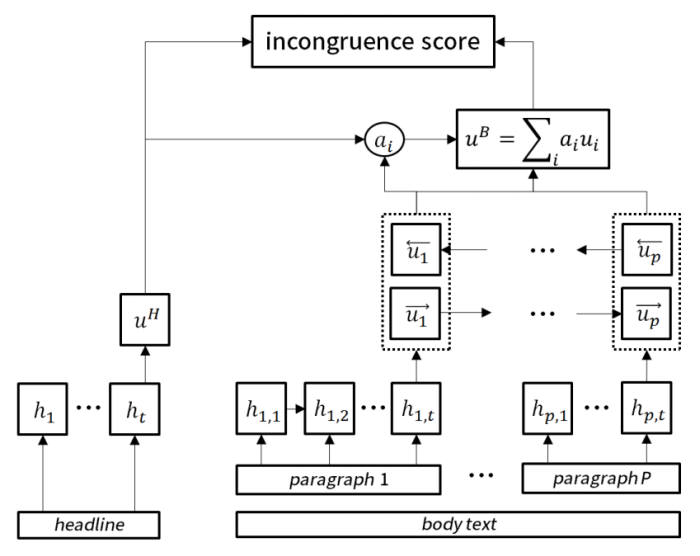
이 모델은 딥러닝 학습 모델인 '순환신경망(RNN)'을 이용해 기사 내부 정보만으로 내용이 일관성을 띠는지 파악하고, 문단 구조와 단어 나열에 따른 의미를 따져 제목과의 관계를 파악한다.
RNN은 여러 개 정보를 처리할 때 이전 단계를 기억해서 다음 과정에 활용하는 것이 특징으로, 단어들이 모여 의미를 띠는 기사 분석에 능하다.
연구팀은 여기에 '어텐션(주목) 기법'을 적용, 모델 정확도를 높였다. 이 기법은 어느 부분·위치에 주목해야 모델 정확도를 높일 수 있는지 선제적으로 파악한다. 200만건에 이르는 기사로 훈련 데이터셋을 만들어 학습도 진행했다.
모델 정확도는 90%가 넘는다. 외부 도움 없이 모델만으로 전체 기사에서 낚시성 기사 대부분을 찾아낼 수 있다. 주된 활용처로는 포털이나 검색 사이트 내 자동 기사 분석 부가서비스를 들 수 있다. 학술 분야에도 쓸 수 있다.
연구팀은 오는 27일 미국 하와이에서 열리는 인공지능(AI) 분야 톱 콘퍼런스 'AAAI-19'에서 연구 성과를 발표한다.
추가 연구에도 힘쓰고 있다. 연구 최종 목표는 100% 가까운 판별 정확도를 구현하는 것이다. 연구팀은 사람 직관 수준으로 기사를 파악할 수 있도록 연구를 거듭하고 있다.
차 교수는 “이번 성과는 간편하게 기사 내적 요소만을 활용해 낚시성 기사를 가려낼 수 있는 것이 장점”이라면서 “대중이 기사를 전적으로 믿을 수 있도록 돕는 서비스 구현이 가능해진다”고 설명했다.